by KeeeX | Jun 3, 2016 | News, Press Release, White Paper
The concept of a Blockchain, this unforgeable ledger freely available to all over the internet, provides the framework that allowed the crypto currency Bitcoin to emerge and operate. This is a tremendous innovation because the network of miners that secure the blockchain is in theory totally insensitive to any pressure, and the theoretical cost of attacking this network is very high (one million dollars per day is a frequently seen figure, not including many more other difficulties).
The idea of an autonomous peer to peer system has proved its resilience in the past. The BitTorrent protocol is a good unstoppable example. The idea of protecting data using cryptographic computations also proved its usefulness, as illustrated by BitTorrent again, and the Git version management system. Bitcoin validates its underlying blockchain in the most spectacular way : the system operates since 2009 with a market capitalization that tops $8.5B at the time of this writing. Bitcoin may well be the most attacked cryptographically based solution on earth.
It has become common to compare Bitcoin with electronic gold, since this currency is by design limited in volume, and its blockchain is more adapted (today) to a limited number of large transfers rather than to many micro transactions. However, with its robustness, this blockchain is also suitable for recording unforgeable proofs of existence, registered for eternity.
Every identifier, every code representing a virtual or real item may find its way to the blockchain, at the date given by the worldwide consensus of blockchain miners.
One may thus notarize (smart) diplomas, bills, contracts, pictures, proofs of insurance claims, identity, ownership. The applications are numerous to environments structurally devoid of trusted tiers. For instance, geographic areas having no land registry can be equipped straightforwardly. The blockchain allows for absolute confidence between individuals who do not know each other.
So, the most positive look that we can have on this technology is naturally ethical. The blockchain not only appears as an enabler, a source of savings, but also as a foundation for pacified relationships, within the economy, the industry, with official administrations, and for the respect of individual rights. This is so because, by granting a proof of existence to an entity, contract, signature, decision, agreement… at a given time, and without any risk of fraud, the blockchain eliminates up to the temptation of bad faith or lies.
The blockchain hence becomes an immaterial handshake, a man to man agreement even in a distance. A simple chat, once notarized, becomes an indisputable contract. The blockchain turns the virtual world again into the village that it had ceased to be.
by KeeeX | Feb 1, 2016 | What KeeeX is For, White Paper
KeeeX addresses a large number of Records Management (Wikipedia) issues as stated in this Wikipedia definition page. Let’s review some of them:
Concerning Digital Records
…It is more difficult to ensure that the content, context and structure of records is preserved and protected when the records do not have a physical existence. This has important implications for the authenticity, reliability, and trustworthiness of records…
KeeeX proves integrity, authenticity, authorship of virtually any digital content.
Particular concerns exist about the ability to access [and read] electronic records over time
KeeeX identifiers are indexed by search engines, hence allowing for unprecedented accessibility and robustness to renaming and moving.
Privacy, data protection, and identity theft have become issues of increasing interest.
KeeeX leaves files where originals are. No transfer is made for processing. When files need to be transferred, they are encrypted end to end. KeeeX implements digital signatures that prevent for identity theft as well.
The increased importance of transparency and accountability in public administration, marked by the widespread adoption of Freedom of Information laws, has led to a focus on the need to manage records so that they can be easily accessed by the public.
KeeeX allows for publishing documents that can be accessed by search engines, and hence made freely available to the public, who can verify their integrity for free. Check for instance this search: https://duckduckgo.com/?q=”xofos-bafek-zebug”.
Implementing required changes to organizational culture is a major challenge, since records management is often seen as an unnecessary or low priority administrative task that can be performed at the lowest levels within an organization.
Using KeeeX, documents are classified and protected as part of everyday work and do not require extraneous actions.
A difficult challenge for many enterprises is tied to the tracking of records through their entire information life cycle so that it’s clear, at all times, where a record exists or if it still exists at all.
KeeeX will help track all successive versions of a record. Each specific version can be meta searched anywhere, including on a company’s disks, to assess whether the file still exists or not.
The tracking of records through their life cycles allows records management staff to understand when and how to apply records related rules, such as rules for legal hold or destruction.
Specific rules can be attached to records either informally in embedded descriptions of more formally using classifiers. It becomes possible, even in the absence of any tool, to track on company’s disks and servers all record instances that should be legally present or that should legally have been deleted.
Concerning Physical Records
Records must be stored in such a way that they are accessible…
When a physical record has been scanned, it may naturally receive the KeeeX identifier of this scan, that can be used for storing and retrieving. This is so because these identifiers are humanized, and hence can be subject to alphabetical sorting. Such an archival strategy is considerably more robust to mis-classification than hierarchical folder archival.
(this complements a document previously published on Slideshare and this blog. As a proof that KeeeX provides unprecedented records management possibilities, you may try this web search: https://duckduckgo.com/?q=xofos-bafek-zebug)

by KeeeX | Jan 30, 2016 | White Paper
Thursday January the 28th was #DataPrivacyDay (or #DataProtectionDay).
CEO, CTO, CIO, CFO, did you take any action?
Do you really still use email ???
Stop leaking your IP on email, untrusted clouds and collaboration solutions.
Stop leaking your IP with co-workers taking work at home using an untrusted synchronization system.
What will happen when you wish to file a patent and some obscure company has beaten you in the race with obvious cheating?
Start using KeeeX, the only durable, risk free, investment free, no-tie in, #nocloud, #nosaas, trusted zero knowledge message+content+process management solution that lets your colleagues send work anywhere, home inclusive, at no risk.

by KeeeX | Jan 27, 2016 | News, Tech Zone, What KeeeX is For, White Paper
Two innovations that illustrate applications of immutable and connected data tend to widely disseminate in our lives. Can we complement or improve on this and what do we learn?
One is Git. Git is the most widely used version control system. The emphasis of Git on data integrity builds upon an underlying scheme called “content addressable storage” and Merkle trees.
(more…)

by KeeeX | Nov 23, 2015 | White Paper
The current trend in mobile device use at work leads to install ever increasing numbers of apps, for multiple uses, from Business Intelligence to Messaging. Some corporate tools are connected to centralized information sources and hence do not result in duplicated data silos. Other don’t.
When apps help users produce valuable data, it is a problem when this data cannot be seamlessly exploited by other, maybe future unknown processes. Disconnected data silos yield disconnected processes. Disconnected processes increase total cost of ownership far beyond the expected initial price tags.
The reason why apps create isolated data silos is because they are not designed to share the data they create. Most often the data is uploaded to the cloud for exploitation, or sometimes stored in a local database. More specifically, SaaS web apps just cannot by design freely access the local drive for obvious security reasons. So data must go to the cloud or a local database. Of course, syncing, collaboration applications must use data cloud stores to present the data to multiple parties.
So the situation is as follows: we need (collaboration) apps for productivity, but using the new trendy (and probably best) app will add one brick to future disconnected processes.
One solution to this problem is to reverse the perspective: instead of placing data inside trusted organizing silos, place trust and organization inside data, so that data can live in the open, outside of any silo, available for unlimited processes, unlimited future exploitation. This is what we are doing at KeeeX.
by KeeeX | Oct 9, 2015 | What KeeeX is For, White Paper
At KeeeX, we are leveraging a patented innovation allowing to augment virtually any file with integrity/authenticity/linking cleartext searchable metadata that opens new perspectives for Open Access (and more generally Open Data).
- file integrity and authorship are builtin.
- references to other papers and documents, semantic classification and context are builtin.
- wherever a file is found, it can be verified as genuine using our simple client or a web site.
This means that:
- Open Research can be published *anywhere*: including a publicly available cloud folder.
- Open Access documents can be retrieved using general purpose search engines.
- any document that refers to another document, if keeexed, will allow to embed the exact identifier to its references, that can themselves be searched then verified locally as genuine.
Of course we provide a paid solution for businesses, but also we develop an academic program, and in any case producing some amount of publishable documents will be possible using the free version.
I’d be extremely happy to help anyone reading this to test KeeeX, for instance in the purpose of studying its potential in Open Access.
If you’re an academic and are willing to use KeeeX in your institute, please feel free to contact us.
This post was created as a comment to a discussion about the future of Open Access publishing.

by KeeeX | Oct 6, 2015 | News, White Paper
Do you believe too that bringing the productivity and agility benefits of social collaboration to the enterprise must necessarily imply using SAAS applications? (more…)

by KeeeX | Jun 23, 2015 | Tech Zone, White Paper
KeeeX is a true solution devoid of trusted tiers, and is not the next ‘Bad Guy’. You have access to everything, even in the future should the KeeeX company default. And KeeeX does not see a byte of your Data. (more…)

by KeeeX | Jun 22, 2015 | News, White Paper
Many, many sources compare the current rush to (Big, Open, …) Data to the Gold Rush. (more…)

by KeeeX | Oct 13, 2014 | News, White Paper
Collaborating efficiently first requires that all participants view the same documents. This is not so obvious in general after a few rounds of exchanging documents by multiple ways, once via a cloud, once by email, once on a usb key… Even by email alone. The multiplication of versions, the difficulty of sharing the precise versions of other contextual documents present as implicit or explicit references, progressively renders the task of knowing what we are working with a challenge when not a nightmare.
More aspects of collaboration amount to accountability (who did this), notifications (when) and formal approval/signature processes.
This white paper attempts to give a hint of how KeeeX addresses these issues in the most lightweight and seamless way ever.
Ensure file equality
Efficient collaboration first requires that all participants work on the same documents. This can never be ensured using conventional file sending/sharing workflows, where unwanted mistakes most often causes errors.
The current approach to this problem amounts to massive centralization, of apps and storage, through centralized servers (as e.g. Google for work), or at least via cloud sharing (box apps, apple iCloud).
KeeeX offers a simple alternative, whereby files can be verified as unmodified by all participants. Verification works locally, hence is immune to any kind of man in the middle attack, and does not expose potentially strategic data to the cloudLink references
Producing knowledge requires huge amounts of more input knowledge. As important as knowing what we are reading is to know what references we have and maybe share. Being able to access the exact same reference document as another participant is key to collaboration.
Current ECM solutions manage this at the expense of huge centralized databases, either deployed company wide or available via SAAS solutions.
KeeeX lets you embed references inside documents themselves.Then, these references can be navigated, exactly like you click and search on the internet. All participants in a collaboration gain the unique possibility of reading references when they are readily available, or searching or requesting an exact copy to a collaborator.Manage Versions
Collaborating requires a careful naming and managing of file versions. Standard user process names versions by using numbers, most often cluttered by project accidents
“This is v2b3-by laurent after meeting”
Again, current ECM solutions manage this at the expense of huge centralized databases, either deployed company wide or available via SAAS solutions.
KeeeX innovates by placing a link to the previous version in every document. There can be several previous, and of course several ‘next’ versions. KeeeX tracks this information to deliver instant navigation to the latest version. KeeeX also uses notifications to track versions before they are actually present on your machine. So should you decide to start upgrading what you think is the latest, you will be warned that it isn’t.Ensure Authorship and Accountability
Accountability is a key item in data governance. Being able to know who is the author of a given document’s alteration is essential.
KeeeX inserts in every keeexed document a reference to its author (most often the user who does the keeexing is indeed the author). The version history of a document make the picture perfectly clear. Should a difference finding program be required to pinpoint the precise differences, KeeeX makes it ultimately accurate, because there can be no doubt about which files must be compared.Be Notified
When a document is shared or sent for review, agreement, or upgrade to collaborators, it is essential that the author, or maybe every person in the sharing group, to be informed about relevant activity.
KeeeX will notify the author every time a user verifies his document, then will notify of any new version.Deal with standard processes
Standard document processes comprise collective agreement, digital signature round, peer reviewing etc.
Such processes are commonly offered through SaaS solutions, as e.g. Docusign, Contract Live…
KeeeX helps tracking the comments, agreements or rejects relative to documents by using the possibility to link notes to the original document, and dynamically listing these notes. Digital signatures can be inserted into any file format supporting picture embedding (as does pdf and most office formats), so as to create a chain or set of digitally signed versions.Conclusion
Efficient collaboration requires tools and services now offered through centralized solutions, whether they are corporate wide database systems, or web service enabled.
KeeeX invents the social, connected, trusted document. It does so by embedding trust, organization, authorship, links to references. Yes, inside every document.
by KeeeX | Sep 26, 2014 | News, White Paper
When collaboration involves sharing or sending documents, many unpleasant situations may arise, even between trusted, non evil participants:
- I think I send the correct file, but I am wrong
- I send the correct file but the recipient mistakenly edits the document while being discussed
- I send the correct file, but I mistakenly edit and save the document after sending
- I have shared a file using a cloud or web sharing or usb or else and cannot find the reference original any more
- I am stuck in a list of manually numbered draft versions and cannot retrieve the correct file to start editing from
- I have printed or exported my document and the editor claims it has changed, so I don’t know which version is currently opened
- …
Trusting a tier to solve the problem
One option is to ask a trusted tier to manage the documents. This can be a web site offering software as a service file management (e.g. google docs, hyper office, or more specifically contract live, or Intralinks (data rooms) to name a few). Or this can be one of the many data cloud systems available.
Trusted tiers like web sites or cloud systems (are trusted to) present the very same version to everyone, which solves part of the problem. They may also deal with versioning. The biggest concern remains that trusting a tier or a web site may not be the proper means of sharing or sending data, should your company be very sensitive to protecting its IP or secrets, and remain safe from copyright laws or unacceptable terms of use.
Also, even with the most secure cloud systems, there remains the difficulty of finding the exact file version entering into a discussion, and once a document was found, warrant that it has never changed.
None of the existing systems ensure that one can easily find within his own file system or cloud the exact version of a document being discussed, without being connected and without a sophisticated database software.
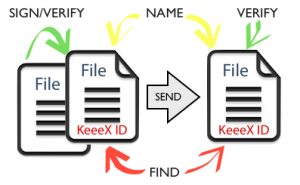
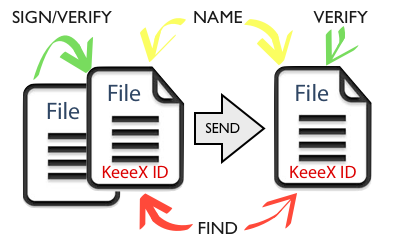
What about trusting the data itself?
A simple key to this collaboration nightmare is achieved as soon as you can ensure offline that a document has never changed, and contains an identifier unique at universe scale that simultaneously allows for
- naming the file in a discussion
- referencing the file in another
- indexing by content
- checking that it never changed
- proving authorship
Let’s analyse a possible implementation of these features:
- imagine this identifier can be pronounced, so you may uniquely name the file when collaborating
- think that this indexed identifier is built from unnatural 5 letter words, e.g. ’xosof’, or ’hemek’, that allow ultra fast and accurate searches using a few letters
- expect that any change to the file will be detected
- of course ensure that the file will still be opened, edited, as usual
- permit a file to embed references to others, versions, semantic context, in a place and under a format that allows further indexing
There are possible metaphors to what is presented here:
- the identifier can be seen as a file ’DNA’, that uniquely represents it
- files are ’read only’ at web sharing scale since, if edited, they are identified as such, and retrieving a non edited version is easy
- the identifier of a file represents the entire set of its copies
- a file is an object, having identity and integrity, pointing to others
This yields numerous benefits
This scheme allows files:
- to be found as a snap
- to embed provable authorship information
- to be verified as never modified
- to be named easily so that collaborators warrant that they read the same document
All this requires no infrastructure, no change in workflow or processes, and provides immediate and massive ROI.
This is what KeeeX offers. Free to test now at keeex.me. Private alpha on invitation – please ask if interested.
This post is a repost from LinkedIn and a follow up to ’Of Semantics and Trust’ (also on LinkedIn). Also on my web site.

by KeeeX | Sep 26, 2014 | News, White Paper
This post highlights the unique contribution of KeeeX to solving the content chaos issue, hence materializing the tremendous ROI and productivity that can be expected from eliminating its consequences, know as the knowledge work deficit. This can be obtained using the most seamless, non intrusive idea for ’knowing what you know’ (quoting former Hewlett-Packard CEO Lew Platt : “If only HP knew what HP knows, we would be three times more efficient.”).
The Content Chaos
Increasingly many sources refer to ’information chaos’ or ’content chaos’ as the prevailing and increasing situation in industry where exponential amounts of data and documents pile up in front of information workers. More precisely, the content chaos stemming from an inability to manage unstructured or standalone documents is an issue to many organizations.
The multiplication of storage and sharing possibilities (e.g clouds, backups, online or not) for data don’t ease the task. They make it impossible to trace the flow of arguments and validations that led to a specific decision, and very often simply to find the expected data.
A number of important figures gatherered over the last years draw a rather dull picture of the situation and how it is perceived. For instance AIIM’s 2011 ECM Survey revealed that:
- 60% of new ECM users are not confident that “e-mails related to documenting commitments and obligations made by their staff are recorded, complete and retrievable.”
- 41% cite content chaos as the trigger for adopting ECM.
- 56% are not confident that their electronic information (excluding e-mails) is “accurate, accessible and trustworthy.”
Content chaos at the individual level
Content chaos impacts everyone at every level. Frequently cited are the increasing pains of:
- finding a known to exist document
- ensuring that a document is in the correct (latest, not accidentally modified) version
- guaranteeing that their correspondent reads the same document
- making their way through a number of duplicates, archives, cloud systems where the data may reside, or is duplicated, maybe with distinct and inaccurate modification dates
- …
The Knowledge Work Deficit
Companies and individuals pay the price of content chaos. The concept of ’knowledge work deficit’ was coined by a 1999 IDC report that revealed that the average yearly cost per employee of searching data was 5000$ (3600€) in 1999.
This report also showed that considering an average sized company having 1000 information workers paid an average 80K$ (60K€),
- the cost of not finding data was 6000$,
- the cost to redo was 12000$.
Not to mention the missed opportunities resulting from low productivity and failed time to market. Of course, some issues relate to paper management, but handling dematerialized documents and numeric data in general has not proven to be a relief in the recent years.
Henceforth a solution allowing perfectly accurate instant searches, without ever needing to redo, would under those settings yield an average 23000$ (so approximately 30% of 80K). Those figures match a famous quote by former Hewlett-Packard CEO Lew Platt that “If only HP knew what HP knows, we would be three times more efficient.”
A wider set of figures has been collected more recently:
- the fortune 500 companies lose an estimated 12B$ by not finding data.
- 59% middle managers say they miss important data everyday because it exists in the company but they cannot find it (from Accenture)
- companies statistically misfile up to 20% of their documents hence lose information forever (ARMA international)
- companies pay six times the cost of the original for searching a lost document (Coopers & Lybrand)
- companies pay eleven times the cost of the original for redoing a lost document (id)
- 90% of typical office tasks revolve around the gathering and distribution of paper documents. 15% of all papers are lost, 30% of the time is used trying to find these lost documents (Delphi Group,1999)
- and executives spend a statistical average of six weeks per year searching for lost documents, according to a survey of 2,600 executives by worldwide office supply leader, Esselte
These figures clearly show that any lightweight seamless solution to address content chaos is subject to extremely high ROI. Let’s introduce KeeeX.
Knowing what you know: the KeeeX way
In essence, solving the content chaos issue amounts to a few simple properties, that pertain to well known data governance guidelines:
- existing documents must be easily found, then verified as non corrupt
- authors can be traced
- decision and version history can be traced
- references to other documents must be easily found
- the context of a document (references, categories, tags, authors …) can be used to search relevant items
KeeeX achieves this using simplistic means : every file contains a plain text indexable, pronounceable, verifiable identifier, as well as references to:
- a plain text indexable reference to an author profile,
- a date,
- possibly a PKI (public key cryptography) signature
- plain text indexable references to other document’s identifiers
Technically, references differ from identifiers so that a content based search using a web search engine or a machine based search application will separate the documents that define an identifier from the ones that reference it.
That the identifier is pronounceable is extremely interesting to humans: they can talk about file X, version Y, that refers to Z.
To paraphrase the innovation: KeeeX leverages file checking mechanisms to the level of a human friendly yet universe scale indexing scheme.
From raw data to linked documents
KeeeX thus embeds references to documents into other documents. These references are plain text searchable. They also allow when found for verifying that the target was never modified. KeeeX hence translates the “linked data” perspective known to the semantic web to a notion of linked documents.
One difference lies in the fact that with keeex, the metadata are embedded inside the documents. From a ’semantic’ perspective, it means that the document IS the concept. There is no notion of attaching meaning to an item outside of it. In turn, this results of not requiring a complex infrastructure to deal with the metadata.
Metadata enhanced organization
KeeeX provides a unique way to describe any possible semantic or tag based document organization. Each concept or tag can be defined as a document. For instance, the concept ’Data Governance’ can be implemented by a pdf print of the corresponding wikipedia page. When future documents refer to that concept, the intent and meaning can be perfectly understood.
KeeeX thus allows a user or company to define the exact granularity of concepts (or tags, semantic keywords, notions …), as are required to organize data. And this organization is written in the documents themselves, and/or in other documents.
Normally, one only shares a document. Using KeeeX, one also shares organization and veracity. Both the latter notions are normally offered by external infrastructures, and not carried by the documents themselves.
Process friendly
Because KeeeX does not encapsulate documents to inject metadata, but rather exploits a large variety of options to embed plain text metadata into every file format, the files retain their full original functionality.
KeeeX hence remains compatible with any kind of document process / infrastructure / management / sharing tool.
Cloud friendly
Because KeeeX can verify user files offline and locally at any time, it offers to solve part of the cloud/archive chaos. Document clones can be backed up or shared using infinitely many cloud, sharing or backup systems: all copies will possibly verified to test whether they are a truly valid instance of the original.
Knowing that she has several backups of a document may safely allow a user to delete a local version. Indeed, should the document be needed in the future, it will be found in a snap by content based file system or web search engines.
Web friendly
KeeeX lets a user forget about file names. Of course, KeeeX copies the first three words of a file id in the filename at creation time. However, KeeeX does not rely upon this name for searching (indexing is content based), and KeeeX does not rely upon this name for verifying: only the contents matter).
Content indexing is good for the web. Web crawlers may learn to look for keeex idioms even in places where they do not (officially) attempt indexing.
Filename independence is also good for the web. Very often, the files uploaded to a service (e.g. photos on flickr, documents on box etc…) will not be served using the same filename. Also, a file name may simply have been translated to a new language.
Conclusion
KeeeX offers a new paradigm to address the information chaos in the most possibly simple way: by instrumenting files so that they carry the required organization, veracity and authorship.
Forever
(note: this is a repost of http://laurent.henocque.com/ and linkedIn)
References
by KeeeX | Sep 26, 2014 | News, White Paper
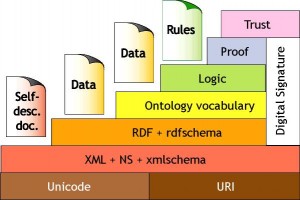
The semantic web offers the promise of a possibly fully automated web of data. What does it take to allow for automating data based agent interactions at web scale? Logic? Trust? Digital Signatures? At what level?
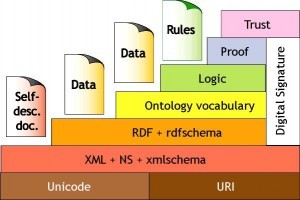
The semantic web stack places trust on top of all, and cryptography / digital signatures on the side. Trust sitting on top of proof hence is greatly impacted by the choice of a logical framework.
It appears here that ‘trust’ refers to trusting people and agents, which more and more now seems to be a ‘not so useful idea’. To illustrate my viewpoint, the reality of man in the middle attacks (see Orange in 2014, the NSA leaks in 2014) makes it obvious that trusting a web site is not enough to fully automate the web. Even in a not automated fashion, the simple fact that you may ‘trust’ your e-something web site and yet that a hacker can present you with a fake login page to steal your credentials is food for though.
Indeed, the digital signature column on the right of the stack tends to illustrate that we need to gain confidence in lower level items than agents. However, I see two flaws here:
- “digital signatures” as of today relates to asymmetric cryptography (also known as PKI – public key infrastructures). It is not quite sure that we need that.
- the column does not go down to the XML layer. It is pretty sure that we would need that..
Why digital signatures are too much?
When automating the interaction between two web agents, having authenticated the author of a program is not key. What matters however is to ensure that the data one receives indeed is what is expected. For instance, a data type definition, if corrupt, would certainly badly impair automation.
So better than asymmetric cryptography allowing for author authentication, we probably do not need much more than symmetric hashes, that can be used to assess data or content integrity. I previously blogged about this issue under the name Trust 3.0.
Why missing the XML layer is wrong?
XML is the most fundamental layer of data in the semantic web. The priority when sending or receiving data is to trust the data itself (as you have understood that we do not care much for the author).
So yes, better than sending / receiving ‘raw’ XML (or JSON, PHP, JAVA or else) we need to trust the data being received. Even more so when sending the xmlschemas that will serve as models for creating/reading data on bothe sides.
Why the choice of a logic is second to trusting data?
We are thinking about programs talking to other programs. What programs understand well are data structures from programming languages. And in most languages, sub typing and sub classing features allow the very kind of basic logic reasoning that currently works in the semantic web (as e.g. using OWL-Lite, a subset of the web ontology language). In that spirit I had the opportunity to suggest disconnecting the SAWSDL recommendation from existing ontology languages.
Henceforth, the semantic web is already potentially alive thanks to all the rest apis that abound. However, every web programmer knows how bad it comes when a web service suddenly decides to expose a different API, adding or removing fields in data structures or function parameters.
What full automation requires in that respect is:
- to trust the exchanged data
- to automatically link data specifications to their new version, thereby potentially allowing a program to automatically adapt to the change
So, semantics equals trusted data?
Consider a pdf version of the wikipedia web page about, say, ‘Freedom‘. If this version is trusted, meaning that no change to the document is possible, two agents may decide to agree that this document indeed denotes the concept of ‘Freedom’. So it seems that trusted data yields semantics under the proper agreement among peers.
On the other hand, consider a situation where semantics are needed (we must know the meaning or structure of data). How can we enforce them? Well, certainly by taking trust down to the level of data alone. So it seems that semantics require trusted data, and that the two are intricately correlated.
(this post was originally featured on laurent henocque’s linkedin profile)

by KeeeX | Sep 24, 2014 | News, White Paper
A rather complete analysis of how well known data governance issues are addressed by KeeeX.