The semantic web offers the promise of a possibly fully automated web of data. What does it take to allow for automating data based agent interactions at web scale? Logic? Trust? Digital Signatures? At what level?
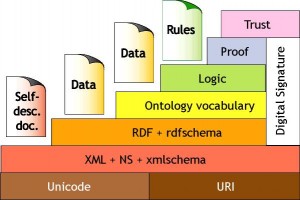
The semantic web stack places trust on top of all, and cryptography / digital signatures on the side. Trust sitting on top of proof hence is greatly impacted by the choice of a logical framework.
It appears here that ‘trust’ refers to trusting people and agents, which more and more now seems to be a ‘not so useful idea’. To illustrate my viewpoint, the reality of man in the middle attacks (see Orange in 2014, the NSA leaks in 2014) makes it obvious that trusting a web site is not enough to fully automate the web. Even in a not automated fashion, the simple fact that you may ‘trust’ your e-something web site and yet that a hacker can present you with a fake login page to steal your credentials is food for though.
Indeed, the digital signature column on the right of the stack tends to illustrate that we need to gain confidence in lower level items than agents. However, I see two flaws here:
- “digital signatures” as of today relates to asymmetric cryptography (also known as PKI – public key infrastructures). It is not quite sure that we need that.
- the column does not go down to the XML layer. It is pretty sure that we would need that..
Why digital signatures are too much?
When automating the interaction between two web agents, having authenticated the author of a program is not key. What matters however is to ensure that the data one receives indeed is what is expected. For instance, a data type definition, if corrupt, would certainly badly impair automation.
So better than asymmetric cryptography allowing for author authentication, we probably do not need much more than symmetric hashes, that can be used to assess data or content integrity. I previously blogged about this issue under the name Trust 3.0.
Why missing the XML layer is wrong?
XML is the most fundamental layer of data in the semantic web. The priority when sending or receiving data is to trust the data itself (as you have understood that we do not care much for the author).
So yes, better than sending / receiving ‘raw’ XML (or JSON, PHP, JAVA or else) we need to trust the data being received. Even more so when sending the xmlschemas that will serve as models for creating/reading data on bothe sides.
Why the choice of a logic is second to trusting data?
We are thinking about programs talking to other programs. What programs understand well are data structures from programming languages. And in most languages, sub typing and sub classing features allow the very kind of basic logic reasoning that currently works in the semantic web (as e.g. using OWL-Lite, a subset of the web ontology language). In that spirit I had the opportunity to suggest disconnecting the SAWSDL recommendation from existing ontology languages.
Henceforth, the semantic web is already potentially alive thanks to all the rest apis that abound. However, every web programmer knows how bad it comes when a web service suddenly decides to expose a different API, adding or removing fields in data structures or function parameters.
What full automation requires in that respect is:
- to trust the exchanged data
- to automatically link data specifications to their new version, thereby potentially allowing a program to automatically adapt to the change
So, semantics equals trusted data?
Consider a pdf version of the wikipedia web page about, say, ‘Freedom‘. If this version is trusted, meaning that no change to the document is possible, two agents may decide to agree that this document indeed denotes the concept of ‘Freedom’. So it seems that trusted data yields semantics under the proper agreement among peers.
On the other hand, consider a situation where semantics are needed (we must know the meaning or structure of data). How can we enforce them? Well, certainly by taking trust down to the level of data alone. So it seems that semantics require trusted data, and that the two are intricately correlated.
(this post was originally featured on laurent henocque’s linkedin profile)