
by KeeeX | Sep 24, 2015 | News
KeeeX was present at World Smart Week on with the Pole SCS.
After being a finalist in two categories, KeeeX won the e-ID & Cybersecurity award.
Laurent Henocque gave two talks there:
by KeeeX | Sep 24, 2015 | Slideshow, Tech Zone
Slides presented at Connect Security World Marseille 2015 (xonom)
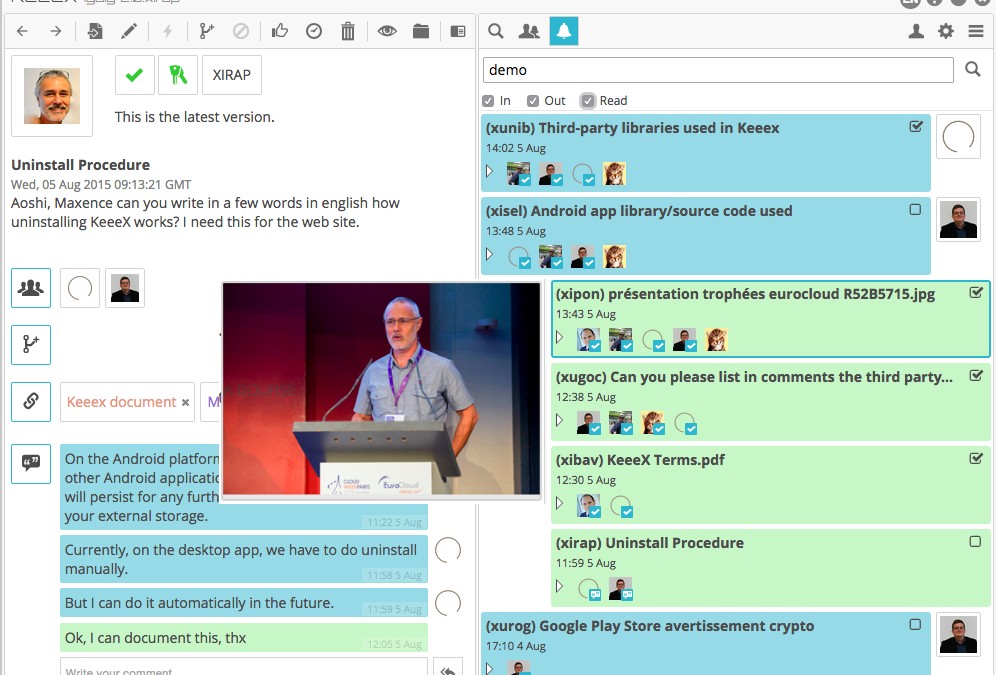
KeeeX lets users define per recipient sharing means (over weblinks, dropbox, google drive, even nfs or webdav) and encryption settings.
Then sharing targets can be selected in a single click: no groups, no access rights, extreme simplicity.
KeeeX is a unique no infrastructure, #nosaas solution.
by KeeeX | Sep 24, 2015 | Slideshow, Tech Zone
These slides were presented at the World e-Id and Cybersecurity conference in Marseille (xuheg)
KeeeX lets users define their own identity settings using a social certificates: people who know you ensure that you are the one you pretend, in the absence of a certificate authority.
Social certificates can be renewed, published, revoked at any time, at no cost.
KeeeX won an award at World Smart Week in the category e-Id and Cybersecurity.
KeeeX is a unique no infrastructure, #nosaas solution.

by KeeeX | Sep 14, 2015 | News
Meet us at World Smart Week, in Marseille, from the 15th to the 17th of September.
KeeeX is finalist in two categories of the Word Smart Week Awards!!!: Digital Identity & Cybersecurity, and Connected Security.
Note that Laurent Henocque is also talking in two collocated events:
World e-Id and Cybersecurity, Identity and Protection Services for Government, Mobility and Enterprise: How Social Certificates May Help Build Decentralized Trust.
and
Connect Security Word, Technologies for Trusted Mobility & Transactions: How One to One Sharing Enforces Secure Collaboration.
by KeeeX | Aug 8, 2015 | News
Well, this incredible release rocks !
You have discovered KeeeX in October 2014 as a unique Content Management System.
Then in February 2014 as a unique private by design sharing solution over any cloud or NFS drive.
Now you probably have the most amazing Enterprise Social Network ever, plus all that precedes.
This is not a beta anymore. Every new or existing personal user account gets two free months, starting now.
For company accounts, please contact us.
Enjoy 🙂
The KeeeX Team, proudly, with many thanks to all who trust and support us in many ways.

by KeeeX | Jul 13, 2015 | Non classé, Slideshow

by KeeeX | Jul 13, 2015 | News
KeeeX was nominated for the
Trophées du Cloud, ending the Cloud Week Paris 2015, in the Startup category . Thanks to the Jury for having understood the innovation in KeeeX and for having given us the chance to deliver this message. And Congrats to the winners.
This nomination adds up to France Entreprise Digital 2015, and the Prix de l’Innovation des Assises de la Sécurité this year.

by KeeeX | Jun 23, 2015 | Tech Zone, White Paper
KeeeX is a true solution devoid of trusted tiers, and is not the next ‘Bad Guy’. You have access to everything, even in the future should the KeeeX company default. And KeeeX does not see a byte of your Data. (more…)

by KeeeX | Jun 22, 2015 | News, White Paper
Many, many sources compare the current rush to (Big, Open, …) Data to the Gold Rush. (more…)

by KeeeX | Jun 19, 2015 | News
The assises de la sécurité website
The Innovation Prize Jury, modalities and Competitors

by KeeeX | Jun 19, 2015 | News
KeeeX was at SmartLife 2015, in a special security track. The event was Held on June the 9-10th in Paris, at the ministry of Economy – Paris Bercy.
Details on the Pole SCS website. The flyer.

by KeeeX | May 27, 2015 | News
We had good news lately (2015 May the 19th exactly): Google indexes Twitter again!
- Yahoo: twitter-google-deal-tweets-search-results
- Digitaltrends: google-twitter-search-results-news
So KeeeX provides the Digital Identity, Twitter provides the Date (and internal search), and Google independently confirms the date and provides global Search
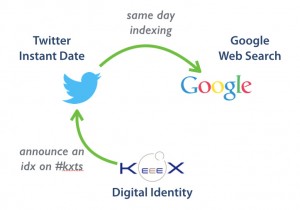
To achieve this, we simply tweet the KeeeX Id of a document, adding the hashtag #kxts (for KeeeX TimeStamping).
So who needs to timestamp? When?
- You’re a Photographer or Poet, Writer… and publish you Art: obtain the proof that you owned the original at a given date
- You’re an Author, and need a proof that you owned a (possibly private) document before you communicate it to a tier
- You’re an Inventor, Researcher, Company, and need a proof that you had an idea or document at a given date
And, yes, there are glorious ancestors, just check Wikipedia on Trusted Timestamping. For instance, Sir Isaac Newton shared the ‘hash’ 6accdae13eff7i3l9n4o4qrr4s8t12ux to Leibniz.
Today, I shared the unique IDX ticeh-mahof-tamob-gucan-lines-kumap…poxut. Via Twitter. Hopefully you will find this with Google.
Have fun timestamping using KeeeX, Twitter, with the help of a global search engine (waiting for more of them to index this kind of content)

by KeeeX | Apr 20, 2015 | News
Sélectionné par le CIP- PACA KeeeX concourt pour France Entreprise Digital dans la catégorie start-up. Nous comptons sur vous pour voter sans modération et nous aider dans le franchissement de ce cap. Clôture des votes le 10 juin
Votez pour KeeeX !
by KeeeX | Jan 27, 2015 | News, Tech Zone
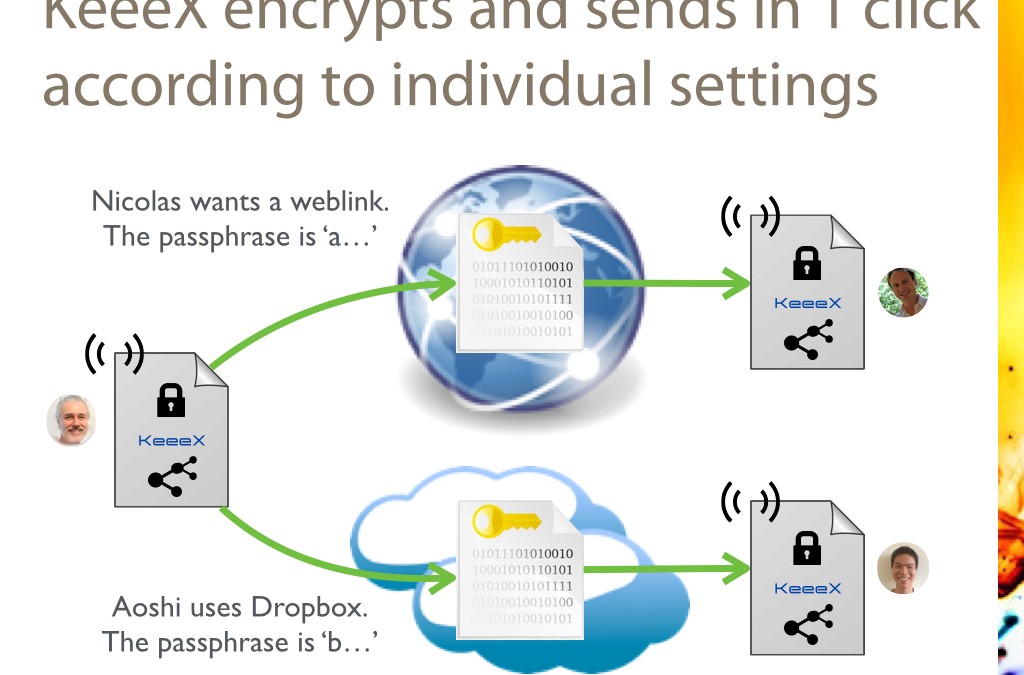
KeeeX beta Lydig 1.7 is online! Now, your files and documents are by default automatically sent via weblinks via a partnership with Jaguar Network, or can be copied to your favorite cloud sync or shared folders.
And they are instantly received, and automatically moved next to their previous version if any.
They are also ultimately protected from prying eyes by automatic client side AES 256 encryption, and automatic receiver side decryption. No stress, no risk in the confidentiality of your industrial of intellectual property.
You pick a shared secret with a collaborator. KeeeX recalls it, as long as you need.

by KeeeX | Jan 6, 2015 | News, What KeeeX is For
The slideshow presented on december the 17th at EMD Marseille during the « La Crise? What Else? » event. You will understand better why KeeeX offers an unprecedented solution of document management, organization, collaboration, multi channel sharing, search, digital signature. And how KeeeX pacifies the digital no man’s land, when our files navigate in between organizations, clouds and folders.

by KeeeX | Oct 24, 2014 | News, Pitch, Slideshow
A pitch sized slideshow illustrating how KeeeX addresses document management in a unique way, solving a large variety of document related pains, from veracity to authorship, sharing, notifications.

by KeeeX | Oct 15, 2014 | News
(Text in french – apologies)
Marseille, le 15 octobre 2014 – La Start-up Marseillaise KeeeX est lauréate du concours PME Innovantes du Numérique PACA 2014, catégorie «Sécurité & Identités Numériques».
Attribué par le pôle de compétitivité mondial SCS – Solutions Communicantes Sécurisées – la Région, les incubateurs et des associations de Provence-Alpes-Côte d’Azur, ce prix récompense le logiciel KeeeX qui simplifie drastiquement l’organisation et le partage de documents numériques.
Avec KeeeX, les utilisateurs trouvent toujours le bon fichier, vite. Finies les pertes de temps et situations confuses au quotidien !
Un passage éclair par l’application KeeeX – action de «keeexer (1)» – et tout fichier (2) se dote de propriétés qui vont grandement simplifier et sécuriser le partage et la collaboration entre collaborateurs, partenaires, clients.
Un fichier keeexé, c’est un document vérifié, dans lequel on peut avoir 100% confiance, sans douter de son auteur, de son contenu, de son authenticité.
Un fichier keeexé, c’est un document connecté, désormais lié à ses différentes versions et à des documents relatifs, selon un contexte par exemple.
Un fichier keeexé, c’est un document social qui, même s’il est publié, échangé ou archivé, reste toujours immédiatement trouvable et garde le contact avec son auteur, sa communauté de lecteurs, notifiant des changements au fil de l’eau (nouvelle version disponible, etc).
KeeeX est une application légère, téléchargeable gratuitement sur http://keeex.me, actuellement disponible en version Beta. Elle est conçue comme un véritable compagnon des utilisateurs, extrêmement simple à adopter et à utiliser, pour une valeur ajoutée maximale immédiate dans les entreprises : gain de temps, gain de productivité, confiance retrouvée.
Ne nécessitant aucune infrastructure, ni tiers de confiance, ni téléchargement sur un service web (cloud), KeeeX se distingue radicalement des solutions de signature numérique et de gestion documentaire du marché.
KeeeX est le fruit de plusieurs années de recherche initiée et menée par son fondateur Laurent Henocque. Brevetée, la technologie de KeeeX est résolument innovante, permettant à tout fichier de contenir ses propres éléments de confiance et d’organisation.
Rendez-vous sur https://keeex.me pour télécharger et tester gratuitement l’application (Beta).
(1) Keeexer : action qui consiste à doter un document de propriétés uniques et innovantes de confiance et d’organisation.
(2) KeeeX accepte un très grand nombre de fichiers courants : bureautique (word, excel, powerpoint, pdf, …), image (jpeg, gif, raw, …), multimédia (mp4, mov, …), informatique (sources, html, …).

by KeeeX | Oct 13, 2014 | News, White Paper
Collaborating efficiently first requires that all participants view the same documents. This is not so obvious in general after a few rounds of exchanging documents by multiple ways, once via a cloud, once by email, once on a usb key… Even by email alone. The multiplication of versions, the difficulty of sharing the precise versions of other contextual documents present as implicit or explicit references, progressively renders the task of knowing what we are working with a challenge when not a nightmare.
More aspects of collaboration amount to accountability (who did this), notifications (when) and formal approval/signature processes.
This white paper attempts to give a hint of how KeeeX addresses these issues in the most lightweight and seamless way ever.
Ensure file equality
Efficient collaboration first requires that all participants work on the same documents. This can never be ensured using conventional file sending/sharing workflows, where unwanted mistakes most often causes errors.
The current approach to this problem amounts to massive centralization, of apps and storage, through centralized servers (as e.g. Google for work), or at least via cloud sharing (box apps, apple iCloud).
KeeeX offers a simple alternative, whereby files can be verified as unmodified by all participants. Verification works locally, hence is immune to any kind of man in the middle attack, and does not expose potentially strategic data to the cloudLink references
Producing knowledge requires huge amounts of more input knowledge. As important as knowing what we are reading is to know what references we have and maybe share. Being able to access the exact same reference document as another participant is key to collaboration.
Current ECM solutions manage this at the expense of huge centralized databases, either deployed company wide or available via SAAS solutions.
KeeeX lets you embed references inside documents themselves.Then, these references can be navigated, exactly like you click and search on the internet. All participants in a collaboration gain the unique possibility of reading references when they are readily available, or searching or requesting an exact copy to a collaborator.Manage Versions
Collaborating requires a careful naming and managing of file versions. Standard user process names versions by using numbers, most often cluttered by project accidents
“This is v2b3-by laurent after meeting”
Again, current ECM solutions manage this at the expense of huge centralized databases, either deployed company wide or available via SAAS solutions.
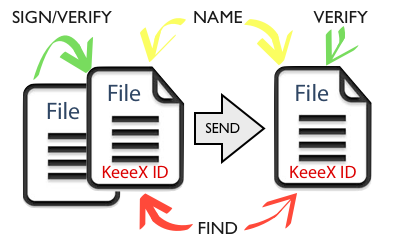
KeeeX innovates by placing a link to the previous version in every document. There can be several previous, and of course several ‘next’ versions. KeeeX tracks this information to deliver instant navigation to the latest version. KeeeX also uses notifications to track versions before they are actually present on your machine. So should you decide to start upgrading what you think is the latest, you will be warned that it isn’t.Ensure Authorship and Accountability
Accountability is a key item in data governance. Being able to know who is the author of a given document’s alteration is essential.
KeeeX inserts in every keeexed document a reference to its author (most often the user who does the keeexing is indeed the author). The version history of a document make the picture perfectly clear. Should a difference finding program be required to pinpoint the precise differences, KeeeX makes it ultimately accurate, because there can be no doubt about which files must be compared.Be Notified
When a document is shared or sent for review, agreement, or upgrade to collaborators, it is essential that the author, or maybe every person in the sharing group, to be informed about relevant activity.
KeeeX will notify the author every time a user verifies his document, then will notify of any new version.Deal with standard processes
Standard document processes comprise collective agreement, digital signature round, peer reviewing etc.
Such processes are commonly offered through SaaS solutions, as e.g. Docusign, Contract Live…
KeeeX helps tracking the comments, agreements or rejects relative to documents by using the possibility to link notes to the original document, and dynamically listing these notes. Digital signatures can be inserted into any file format supporting picture embedding (as does pdf and most office formats), so as to create a chain or set of digitally signed versions.Conclusion
Efficient collaboration requires tools and services now offered through centralized solutions, whether they are corporate wide database systems, or web service enabled.
KeeeX invents the social, connected, trusted document. It does so by embedding trust, organization, authorship, links to references. Yes, inside every document.
by KeeeX | Sep 26, 2014 | News, White Paper
When collaboration involves sharing or sending documents, many unpleasant situations may arise, even between trusted, non evil participants:
- I think I send the correct file, but I am wrong
- I send the correct file but the recipient mistakenly edits the document while being discussed
- I send the correct file, but I mistakenly edit and save the document after sending
- I have shared a file using a cloud or web sharing or usb or else and cannot find the reference original any more
- I am stuck in a list of manually numbered draft versions and cannot retrieve the correct file to start editing from
- I have printed or exported my document and the editor claims it has changed, so I don’t know which version is currently opened
- …
Trusting a tier to solve the problem
One option is to ask a trusted tier to manage the documents. This can be a web site offering software as a service file management (e.g. google docs, hyper office, or more specifically contract live, or Intralinks (data rooms) to name a few). Or this can be one of the many data cloud systems available.
Trusted tiers like web sites or cloud systems (are trusted to) present the very same version to everyone, which solves part of the problem. They may also deal with versioning. The biggest concern remains that trusting a tier or a web site may not be the proper means of sharing or sending data, should your company be very sensitive to protecting its IP or secrets, and remain safe from copyright laws or unacceptable terms of use.
Also, even with the most secure cloud systems, there remains the difficulty of finding the exact file version entering into a discussion, and once a document was found, warrant that it has never changed.
None of the existing systems ensure that one can easily find within his own file system or cloud the exact version of a document being discussed, without being connected and without a sophisticated database software.
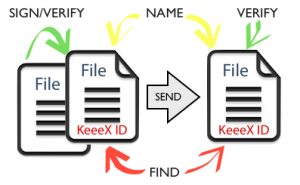
What about trusting the data itself?
A simple key to this collaboration nightmare is achieved as soon as you can ensure offline that a document has never changed, and contains an identifier unique at universe scale that simultaneously allows for
- naming the file in a discussion
- referencing the file in another
- indexing by content
- checking that it never changed
- proving authorship
Let’s analyse a possible implementation of these features:
- imagine this identifier can be pronounced, so you may uniquely name the file when collaborating
- think that this indexed identifier is built from unnatural 5 letter words, e.g. ’xosof’, or ’hemek’, that allow ultra fast and accurate searches using a few letters
- expect that any change to the file will be detected
- of course ensure that the file will still be opened, edited, as usual
- permit a file to embed references to others, versions, semantic context, in a place and under a format that allows further indexing
There are possible metaphors to what is presented here:
- the identifier can be seen as a file ’DNA’, that uniquely represents it
- files are ’read only’ at web sharing scale since, if edited, they are identified as such, and retrieving a non edited version is easy
- the identifier of a file represents the entire set of its copies
- a file is an object, having identity and integrity, pointing to others
This yields numerous benefits
This scheme allows files:
- to be found as a snap
- to embed provable authorship information
- to be verified as never modified
- to be named easily so that collaborators warrant that they read the same document
All this requires no infrastructure, no change in workflow or processes, and provides immediate and massive ROI.
This is what KeeeX offers. Free to test now at keeex.me. Private alpha on invitation – please ask if interested.
This post is a repost from LinkedIn and a follow up to ’Of Semantics and Trust’ (also on LinkedIn). Also on my web site.

by KeeeX | Sep 26, 2014 | News, White Paper
This post highlights the unique contribution of KeeeX to solving the content chaos issue, hence materializing the tremendous ROI and productivity that can be expected from eliminating its consequences, know as the knowledge work deficit. This can be obtained using the most seamless, non intrusive idea for ’knowing what you know’ (quoting former Hewlett-Packard CEO Lew Platt : “If only HP knew what HP knows, we would be three times more efficient.”).
The Content Chaos
Increasingly many sources refer to ’information chaos’ or ’content chaos’ as the prevailing and increasing situation in industry where exponential amounts of data and documents pile up in front of information workers. More precisely, the content chaos stemming from an inability to manage unstructured or standalone documents is an issue to many organizations.
The multiplication of storage and sharing possibilities (e.g clouds, backups, online or not) for data don’t ease the task. They make it impossible to trace the flow of arguments and validations that led to a specific decision, and very often simply to find the expected data.
A number of important figures gatherered over the last years draw a rather dull picture of the situation and how it is perceived. For instance AIIM’s 2011 ECM Survey revealed that:
- 60% of new ECM users are not confident that “e-mails related to documenting commitments and obligations made by their staff are recorded, complete and retrievable.”
- 41% cite content chaos as the trigger for adopting ECM.
- 56% are not confident that their electronic information (excluding e-mails) is “accurate, accessible and trustworthy.”
Content chaos at the individual level
Content chaos impacts everyone at every level. Frequently cited are the increasing pains of:
- finding a known to exist document
- ensuring that a document is in the correct (latest, not accidentally modified) version
- guaranteeing that their correspondent reads the same document
- making their way through a number of duplicates, archives, cloud systems where the data may reside, or is duplicated, maybe with distinct and inaccurate modification dates
- …
The Knowledge Work Deficit
Companies and individuals pay the price of content chaos. The concept of ’knowledge work deficit’ was coined by a 1999 IDC report that revealed that the average yearly cost per employee of searching data was 5000$ (3600€) in 1999.
This report also showed that considering an average sized company having 1000 information workers paid an average 80K$ (60K€),
- the cost of not finding data was 6000$,
- the cost to redo was 12000$.
Not to mention the missed opportunities resulting from low productivity and failed time to market. Of course, some issues relate to paper management, but handling dematerialized documents and numeric data in general has not proven to be a relief in the recent years.
Henceforth a solution allowing perfectly accurate instant searches, without ever needing to redo, would under those settings yield an average 23000$ (so approximately 30% of 80K). Those figures match a famous quote by former Hewlett-Packard CEO Lew Platt that “If only HP knew what HP knows, we would be three times more efficient.”
A wider set of figures has been collected more recently:
- the fortune 500 companies lose an estimated 12B$ by not finding data.
- 59% middle managers say they miss important data everyday because it exists in the company but they cannot find it (from Accenture)
- companies statistically misfile up to 20% of their documents hence lose information forever (ARMA international)
- companies pay six times the cost of the original for searching a lost document (Coopers & Lybrand)
- companies pay eleven times the cost of the original for redoing a lost document (id)
- 90% of typical office tasks revolve around the gathering and distribution of paper documents. 15% of all papers are lost, 30% of the time is used trying to find these lost documents (Delphi Group,1999)
- and executives spend a statistical average of six weeks per year searching for lost documents, according to a survey of 2,600 executives by worldwide office supply leader, Esselte
These figures clearly show that any lightweight seamless solution to address content chaos is subject to extremely high ROI. Let’s introduce KeeeX.
Knowing what you know: the KeeeX way
In essence, solving the content chaos issue amounts to a few simple properties, that pertain to well known data governance guidelines:
- existing documents must be easily found, then verified as non corrupt
- authors can be traced
- decision and version history can be traced
- references to other documents must be easily found
- the context of a document (references, categories, tags, authors …) can be used to search relevant items
KeeeX achieves this using simplistic means : every file contains a plain text indexable, pronounceable, verifiable identifier, as well as references to:
- a plain text indexable reference to an author profile,
- a date,
- possibly a PKI (public key cryptography) signature
- plain text indexable references to other document’s identifiers
Technically, references differ from identifiers so that a content based search using a web search engine or a machine based search application will separate the documents that define an identifier from the ones that reference it.
That the identifier is pronounceable is extremely interesting to humans: they can talk about file X, version Y, that refers to Z.
To paraphrase the innovation: KeeeX leverages file checking mechanisms to the level of a human friendly yet universe scale indexing scheme.
From raw data to linked documents
KeeeX thus embeds references to documents into other documents. These references are plain text searchable. They also allow when found for verifying that the target was never modified. KeeeX hence translates the “linked data” perspective known to the semantic web to a notion of linked documents.
One difference lies in the fact that with keeex, the metadata are embedded inside the documents. From a ’semantic’ perspective, it means that the document IS the concept. There is no notion of attaching meaning to an item outside of it. In turn, this results of not requiring a complex infrastructure to deal with the metadata.
Metadata enhanced organization
KeeeX provides a unique way to describe any possible semantic or tag based document organization. Each concept or tag can be defined as a document. For instance, the concept ’Data Governance’ can be implemented by a pdf print of the corresponding wikipedia page. When future documents refer to that concept, the intent and meaning can be perfectly understood.
KeeeX thus allows a user or company to define the exact granularity of concepts (or tags, semantic keywords, notions …), as are required to organize data. And this organization is written in the documents themselves, and/or in other documents.
Normally, one only shares a document. Using KeeeX, one also shares organization and veracity. Both the latter notions are normally offered by external infrastructures, and not carried by the documents themselves.
Process friendly
Because KeeeX does not encapsulate documents to inject metadata, but rather exploits a large variety of options to embed plain text metadata into every file format, the files retain their full original functionality.
KeeeX hence remains compatible with any kind of document process / infrastructure / management / sharing tool.
Cloud friendly
Because KeeeX can verify user files offline and locally at any time, it offers to solve part of the cloud/archive chaos. Document clones can be backed up or shared using infinitely many cloud, sharing or backup systems: all copies will possibly verified to test whether they are a truly valid instance of the original.
Knowing that she has several backups of a document may safely allow a user to delete a local version. Indeed, should the document be needed in the future, it will be found in a snap by content based file system or web search engines.
Web friendly
KeeeX lets a user forget about file names. Of course, KeeeX copies the first three words of a file id in the filename at creation time. However, KeeeX does not rely upon this name for searching (indexing is content based), and KeeeX does not rely upon this name for verifying: only the contents matter).
Content indexing is good for the web. Web crawlers may learn to look for keeex idioms even in places where they do not (officially) attempt indexing.
Filename independence is also good for the web. Very often, the files uploaded to a service (e.g. photos on flickr, documents on box etc…) will not be served using the same filename. Also, a file name may simply have been translated to a new language.
Conclusion
KeeeX offers a new paradigm to address the information chaos in the most possibly simple way: by instrumenting files so that they carry the required organization, veracity and authorship.
Forever
(note: this is a repost of http://laurent.henocque.com/ and linkedIn)
References