When collaboration involves sharing or sending documents, many unpleasant situations may arise, even between trusted, non evil participants:
- I think I send the correct file, but I am wrong
- I send the correct file but the recipient mistakenly edits the document while being discussed
- I send the correct file, but I mistakenly edit and save the document after sending
- I have shared a file using a cloud or web sharing or usb or else and cannot find the reference original any more
- I am stuck in a list of manually numbered draft versions and cannot retrieve the correct file to start editing from
- I have printed or exported my document and the editor claims it has changed, so I don’t know which version is currently opened
- …
Trusting a tier to solve the problem
One option is to ask a trusted tier to manage the documents. This can be a web site offering software as a service file management (e.g. google docs, hyper office, or more specifically contract live, or Intralinks (data rooms) to name a few). Or this can be one of the many data cloud systems available.
Trusted tiers like web sites or cloud systems (are trusted to) present the very same version to everyone, which solves part of the problem. They may also deal with versioning. The biggest concern remains that trusting a tier or a web site may not be the proper means of sharing or sending data, should your company be very sensitive to protecting its IP or secrets, and remain safe from copyright laws or unacceptable terms of use.
Also, even with the most secure cloud systems, there remains the difficulty of finding the exact file version entering into a discussion, and once a document was found, warrant that it has never changed.
None of the existing systems ensure that one can easily find within his own file system or cloud the exact version of a document being discussed, without being connected and without a sophisticated database software.
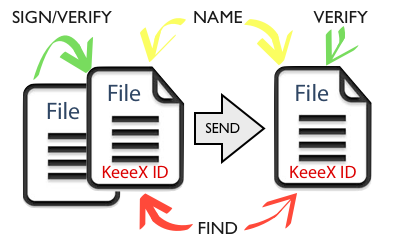
What about trusting the data itself?
A simple key to this collaboration nightmare is achieved as soon as you can ensure offline that a document has never changed, and contains an identifier unique at universe scale that simultaneously allows for
- naming the file in a discussion
- referencing the file in another
- indexing by content
- checking that it never changed
- proving authorship
Let’s analyse a possible implementation of these features:
- imagine this identifier can be pronounced, so you may uniquely name the file when collaborating
- think that this indexed identifier is built from unnatural 5 letter words, e.g. ’xosof’, or ’hemek’, that allow ultra fast and accurate searches using a few letters
- expect that any change to the file will be detected
- of course ensure that the file will still be opened, edited, as usual
- permit a file to embed references to others, versions, semantic context, in a place and under a format that allows further indexing
There are possible metaphors to what is presented here:
- the identifier can be seen as a file ’DNA’, that uniquely represents it
- files are ’read only’ at web sharing scale since, if edited, they are identified as such, and retrieving a non edited version is easy
- the identifier of a file represents the entire set of its copies
- a file is an object, having identity and integrity, pointing to others
This yields numerous benefits
This scheme allows files:
- to be found as a snap
- to embed provable authorship information
- to be verified as never modified
- to be named easily so that collaborators warrant that they read the same document
All this requires no infrastructure, no change in workflow or processes, and provides immediate and massive ROI.
This is what KeeeX offers. Free to test now at keeex.me. Private alpha on invitation – please ask if interested.
This post is a repost from LinkedIn and a follow up to ’Of Semantics and Trust’ (also on LinkedIn). Also on my web site.